Blog
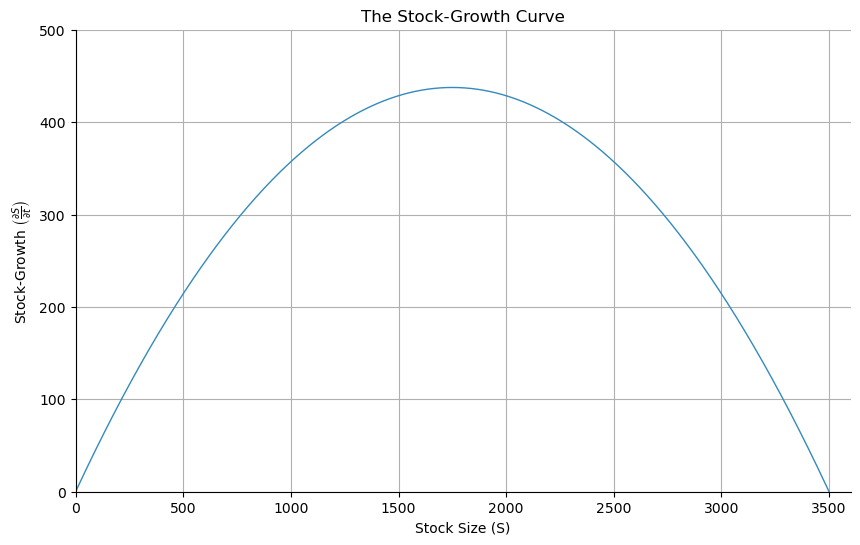

Teaching with Stata
stata
jupyter
reproducible research
literate programming
Reproducible Research and Literate Programming for Econometrics
emacs
orgmode
stata
python
matlab
reproducible research
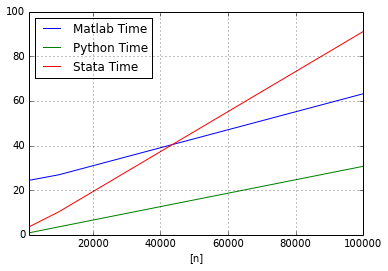
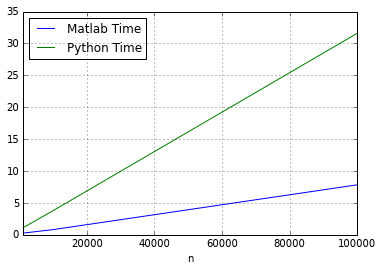
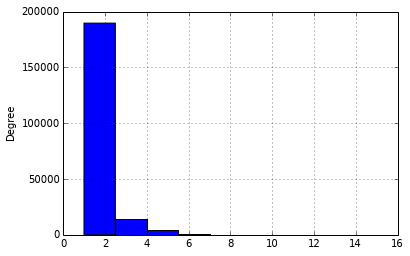
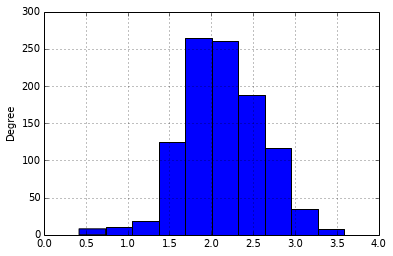
No matching items